The Problem Statement and the proposed Bayesian MMM solution
Consider a company, which runs an online shop, and advertises on seven different paid channels (TV, radio, billboards, Google Ads, etc). Based on weekly data on weekly advertisement costs and revenue available for 2 years, the company would like to understand how effective different channels are. One has to take into account that marketing actions have usually not an immediate effect, ads and campaigns in one week may influence sales in the coming weeks. So different channels can be expected to target different audiences at different times and for different durations, and hence will have lagged effects on revenue.
For this problem, I used a Bayesian Media Mix Modelling approach. MMM can be perfomed with a simpler linear regression approach, however with a bayesian approach, we can find more robust solutions, and estimate confidence intervals. For this work, I took inspiration and used code from the following sources:
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Requirement already satisfied: pymc3 in /usr/local/lib/python3.8/dist-packages (3.11.5)
Requirement already satisfied: patsy>=0.5.1 in /usr/local/lib/python3.8/dist-packages (from pymc3) (0.5.3)
Requirement already satisfied: semver>=2.13.0 in /usr/local/lib/python3.8/dist-packages (from pymc3) (2.13.0)
Requirement already satisfied: cachetools>=4.2.1 in /usr/local/lib/python3.8/dist-packages (from pymc3) (5.3.0)
Requirement already satisfied: arviz>=0.11.0 in /usr/local/lib/python3.8/dist-packages (from pymc3) (0.12.1)
Requirement already satisfied: fastprogress>=0.2.0 in /usr/local/lib/python3.8/dist-packages (from pymc3) (1.0.3)
Requirement already satisfied: deprecat in /usr/local/lib/python3.8/dist-packages (from pymc3) (2.1.1)
Requirement already satisfied: numpy<1.22.2,>=1.15.0 in /usr/local/lib/python3.8/dist-packages (from pymc3) (1.21.6)
Requirement already satisfied: pandas>=0.24.0 in /usr/local/lib/python3.8/dist-packages (from pymc3) (1.3.5)
Requirement already satisfied: typing-extensions>=3.7.4 in /usr/local/lib/python3.8/dist-packages (from pymc3) (4.4.0)
Requirement already satisfied: scipy<1.8.0,>=1.7.3 in /usr/local/lib/python3.8/dist-packages (from pymc3) (1.7.3)
Requirement already satisfied: theano-pymc==1.1.2 in /usr/local/lib/python3.8/dist-packages (from pymc3) (1.1.2)
Requirement already satisfied: dill in /usr/local/lib/python3.8/dist-packages (from pymc3) (0.3.6)
Requirement already satisfied: filelock in /usr/local/lib/python3.8/dist-packages (from theano-pymc==1.1.2->pymc3) (3.9.0)
Requirement already satisfied: matplotlib>=3.0 in /usr/local/lib/python3.8/dist-packages (from arviz>=0.11.0->pymc3) (3.2.2)
Requirement already satisfied: packaging in /usr/local/lib/python3.8/dist-packages (from arviz>=0.11.0->pymc3) (23.0)
Requirement already satisfied: xarray>=0.16.1 in /usr/local/lib/python3.8/dist-packages (from arviz>=0.11.0->pymc3) (2022.12.0)
Requirement already satisfied: xarray-einstats>=0.2 in /usr/local/lib/python3.8/dist-packages (from arviz>=0.11.0->pymc3) (0.5.1)
Requirement already satisfied: setuptools>=38.4 in /usr/local/lib/python3.8/dist-packages (from arviz>=0.11.0->pymc3) (57.4.0)
Requirement already satisfied: netcdf4 in /usr/local/lib/python3.8/dist-packages (from arviz>=0.11.0->pymc3) (1.6.2)
Requirement already satisfied: python-dateutil>=2.7.3 in /usr/local/lib/python3.8/dist-packages (from pandas>=0.24.0->pymc3) (2.8.2)
Requirement already satisfied: pytz>=2017.3 in /usr/local/lib/python3.8/dist-packages (from pandas>=0.24.0->pymc3) (2022.7.1)
Requirement already satisfied: six in /usr/local/lib/python3.8/dist-packages (from patsy>=0.5.1->pymc3) (1.15.0)
Requirement already satisfied: wrapt<2,>=1.10 in /usr/local/lib/python3.8/dist-packages (from deprecat->pymc3) (1.14.1)
Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.8/dist-packages (from matplotlib>=3.0->arviz>=0.11.0->pymc3) (3.0.9)
Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.8/dist-packages (from matplotlib>=3.0->arviz>=0.11.0->pymc3) (1.4.4)
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.8/dist-packages (from matplotlib>=3.0->arviz>=0.11.0->pymc3) (0.11.0)
Requirement already satisfied: cftime in /usr/local/lib/python3.8/dist-packages (from netcdf4->arviz>=0.11.0->pymc3) (1.6.2)
import arviz as azimport matplotlib.pyplot as pltimport mathimport numpy as npimport pandas as pdfrom prophet import Prophetimport pymc3 as pm3import seaborn as snsimport theanoimport theano.tensor as ttfrom sklearn.preprocessing import MinMaxScalerfrom sklearn.metrics import mean_absolute_error, mean_absolute_percentage_error
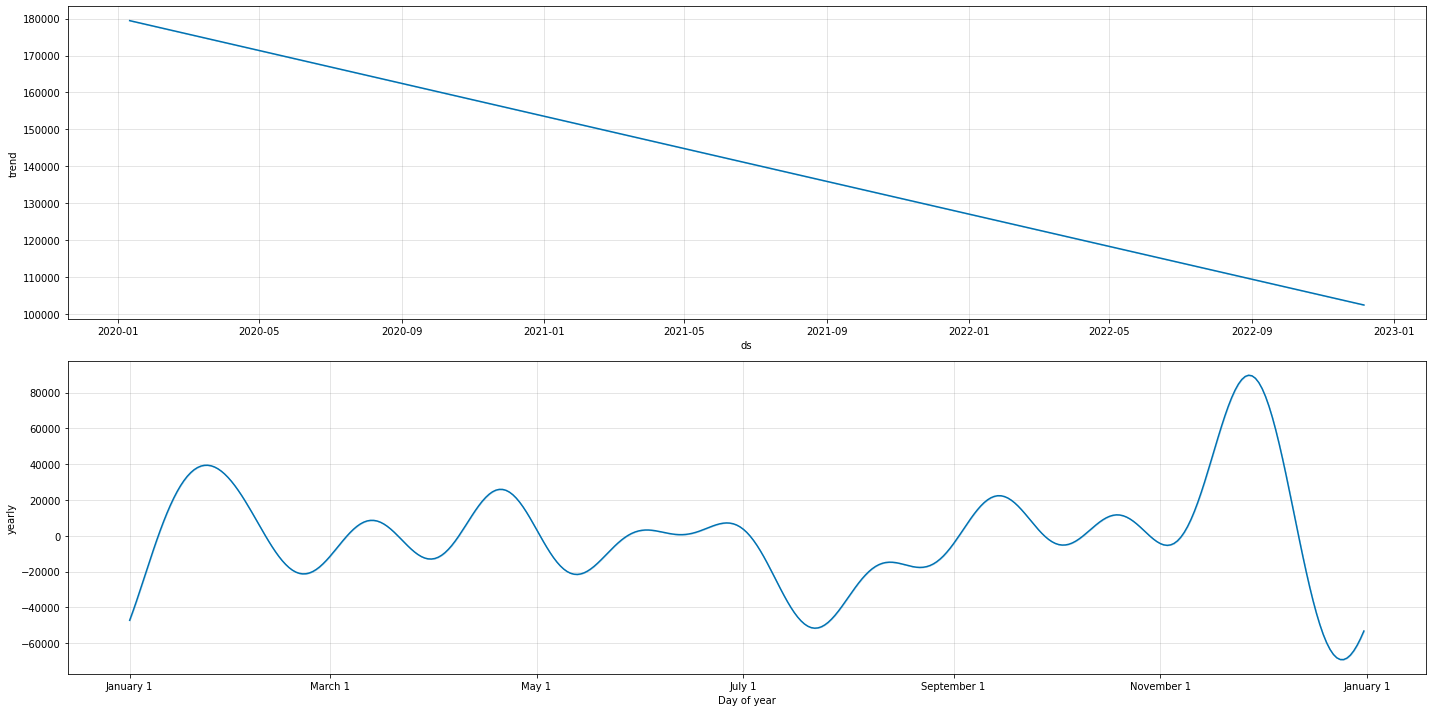
Adding the detected trend and seasonality signals back to the data table:
prophet_columns = [col for col in prophet_predict.columns if (col.endswith("upper") ==False) & (col.endswith("lower") ==False)]final_data = data_wdates.copy()final_data["trend"] = prophet_predict["trend"]final_data["season"] = prophet_predict["yearly"]
The final feature (X) and target (y) data:
X = final_data.drop(columns=['revenue', 'start_of_week'])y = final_data['revenue']
The Model
Carryover (adstock)
For modelling carryover, following Jin et al. 2017, we use an adstock function of form:
where, \(w_m\) describes the weight of the effect on each time step \(l\), that lasts for \(L\) time steps (which we here prescribe to be 13 time steps, i.e., weeks, which is a good approximation for infinity according to Jin et al. 2017), and \(\alpha_m\) is the decay rate for the channel \(m\).
In order to account for potential delays in the media effects, following Jin et al. 2017 again, we can add \(\theta_m\), the delay of the peak effect for the media channel \(m\) into the equation above as follows:
def adstock_weights(alpha, theta, length=13, delayed=False):if delayed: w = [tt.power(alpha, tt.power(i-theta,2)) for i inrange(length)]else: w = [tt.power(alpha, i) for i inrange(length)] w = tt.as_tensor_variable(w)return w
def carryover (x, alpha, theta=0, length=13, delayed=False): w = adstock_weights(alpha, theta, length, delayed) x_lags = tt.stack( [tt.concatenate([tt.zeros(i),x[:x.shape[0]-i]]) for i inrange(length)] )return tt.dot(w, x_lags)
Next, we build a model that consists of delayed media channels and control variables:
where, \(\epsilon\) and \(\tau\) represent noise and baseline revenue, \(z_{t,c}\) and \(\gamma\) represent the control variable \(c\) and their effects, and \(x^*_{t,m}\) and \(\beta_m\) represent the (adstocked) media spending \(m\) and their effects, respectively.
Note that here for simplicity, we assume no shape effects (i.e., no saturation). We further assume that marketing contributions can only be positive, which can be achieved by drawing the contribution coefficient from a half-normal distribution.
Media channels: Adding spend_channel_1
Media channels: Adding spend_channel_2
Media channels: Adding spend_channel_3
Media channels: Adding spend_channel_4
Media channels: Adding spend_channel_5
Media channels: Adding spend_channel_6
Media channels: Adding spend_channel_7
Control Variables: Adding trend
Control Variables: Adding season
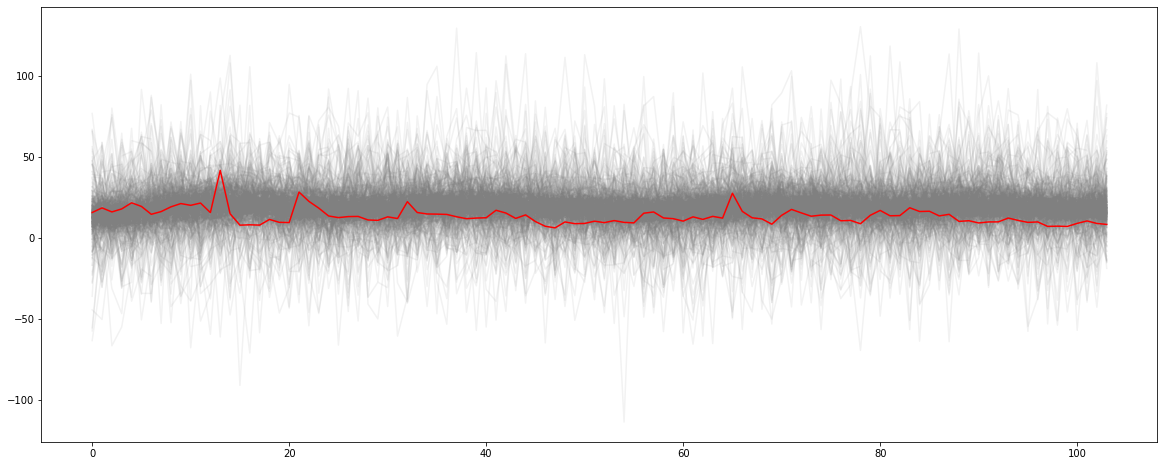
Do the prior distributions make sense?
We can check whether the model estimates based on priors more or less make sense, as can be judged from a rough alignment of the corresponding estimates with the observations.
with mmm1: prior_pred = pm3.sample_prior_predictive()prior_names = [prior_name for prior_name inlist(prior_pred.keys()) if (prior_name.endswith("logodds__") ==False) & (prior_name.endswith("_log__") ==False)]fig, ax = plt.subplots(figsize = (20, 8))_ = ax.plot(prior_pred["revenue"].T, color ="0.5", alpha =0.1)_ = ax.plot(y_transformed.values, color ="red")
WARNING:theano.tensor.blas:We did not find a dynamic library in the library_dir of the library we use for blas. If you use ATLAS, make sure to compile it with dynamics library.
WARNING:theano.tensor.blas:We did not find a dynamic library in the library_dir of the library we use for blas. If you use ATLAS, make sure to compile it with dynamics library.
Check the prior distributions:
#plots priors using the random variablesdef plot_priors(variables, prior_dictionary =None):ifisinstance(variables[0], pm3.model.TransformedRV) ==Falseand prior_dictionary isNone:raiseException("prior dictionary should be provided. It can be generated by sample_prior_predictive") cols =7 rows =int(math.ceil(len(variables)/cols)) fig, ax = plt.subplots(rows, cols, figsize=(15, 3*rows)) ax = np.reshape(ax, (-1, cols))for i inrange(rows):for j inrange(cols): vi = i*cols + jif vi <len(variables): var = variables[vi]ifisinstance(var, pm3.model.TransformedRV): sns.histplot(var.random(size=10000).flatten(), kde=True, ax=ax[i, j])#p.set_axis_labels(var.name) ax[i, j].set_title(var.name)else: prior = prior_dictionary[var] sns.histplot(prior, kde=True, ax = ax[i, j]) ax[i, j].set_title(var) plt.tight_layout()media_coef_priors = [p for p in prior_names if p.startswith("beta")]plot_priors(media_coef_priors, prior_pred)print(f"beta priors: {len(media_coef_priors)}")adstock_priors = [p for p in prior_names if p.startswith("alpha")]plot_priors(adstock_priors, prior_pred)print(f"alpha priors: {len(adstock_priors)}")adstock_priors = [p for p in prior_names if p.startswith("theta")]plot_priors(adstock_priors, prior_pred)print(f"theta priors: {len(adstock_priors)}")control_coef_priors = [p for p in prior_names if p.startswith("gamma_")] + ["base", "noise"]plot_priors(control_coef_priors, prior_pred)print(f"gamma priors: {len(control_coef_priors)}")
array([[<matplotlib.axes._subplots.AxesSubplot object at 0x7f9af5f12400>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7f9af620fd00>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7f9af6554070>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7f9af6680850>],
[<matplotlib.axes._subplots.AxesSubplot object at 0x7f9af6a422e0>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7f9af6afb130>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7f9af6d135b0>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7f9af6bf6ca0>],
[<matplotlib.axes._subplots.AxesSubplot object at 0x7f9af3bbbbb0>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7f9af3bc7280>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7f9af47db640>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7f9af6f9e190>],
[<matplotlib.axes._subplots.AxesSubplot object at 0x7f9af6004550>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7f9af5fe1730>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7f9afafc7730>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7f9af176f490>],
[<matplotlib.axes._subplots.AxesSubplot object at 0x7f9af1789bb0>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7f9af1731310>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7f9af1749a30>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7f9af16f0190>],
[<matplotlib.axes._subplots.AxesSubplot object at 0x7f9af17098b0>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7f9af16a5f10>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7f9af16c97c0>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7f9af1663eb0>],
[<matplotlib.axes._subplots.AxesSubplot object at 0x7f9af16866a0>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7f9af1622dc0>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7f9af1653520>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7f9af15fec40>]],
dtype=object)
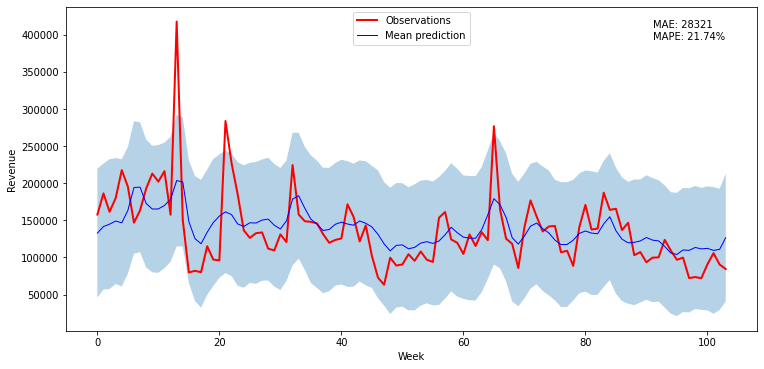
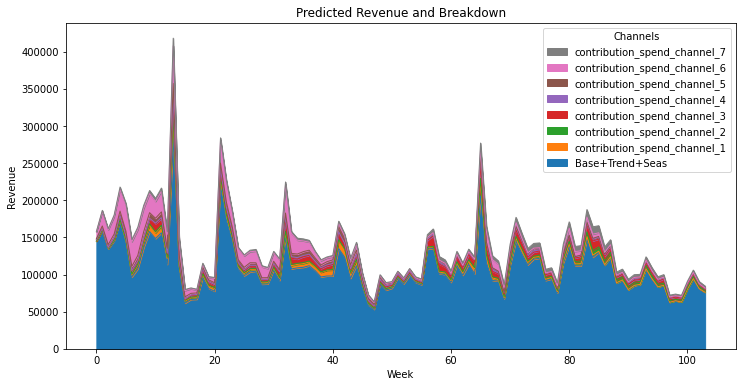
Predictions vs Observations
We can now check the model skill by plotting the predictions and observations together, and calculating, e.g., MAE.
with mmm1: posterior = pm3.sample_posterior_predictive(trace)
Except for two weeks, the observations lay within 2 standard deviations plus/minus the predictions. That instance is likely due to a special event, like a promotion or a holiday, which is not accounted for by the model. The mean absolute error corresponds to about 20% of the revenue.
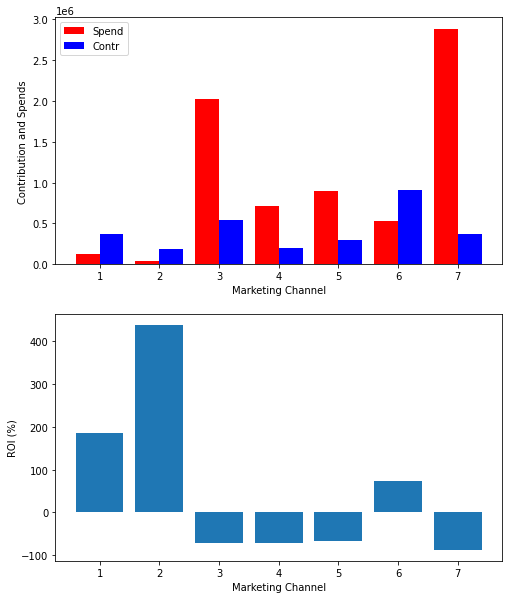
where \(C_{t,m}\) and \(S_{t,m}\) are the revenue contribution and spends to the media channel \(m\) at a given time step (\(t\)).
#Calculate ROI for each channeltotal_contr = adj_contributions.sum(axis=0)total_spend = X.sum(axis=0)Cchannels = [f'contribution_spend_channel_{i}'for i inrange(1,8)]Schannels = [f'spend_channel_{i}'for i inrange(1,8)]ROI_l= [None] *7spend_l = [None] *7contr_l = [None] *7for i inrange(7): spend_l[i] = total_spend[Schannels[i]] contr_l[i] = total_contr[Cchannels[i]] ROI_l[i] = (contr_l[i] - spend_l[i])/spend_l[i] *100fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(8, 10))ax1.bar(np.arange(1,8) -0.2, spend_l, color ='r', width =0.4, label='Spend')ax1.bar(np.arange(1,8) +0.2, contr_l, color ='b', width =0.4, label='Contr')ax1.set_xlabel('Marketing Channel')ax1.set_ylabel('Contribution and Spends')ax1.legend(loc='upper left')ax2.bar(range(1,8),ROI_l)ax2.set_xlabel('Marketing Channel')ax2.set_ylabel('ROI (%)')plt.show()
Our model suggests that only channels 1, 2 and 6 generate positive net gains. Among these channels, 2 seems most effective in terms of ROI, however, in terms of absolute revenue contribution, channel 6 is the most important source. Among the channels that results in net costs channel 7 is the one that requires most immediate attenion, both in terms of ROI and absolute net cost. Continued investment in channels 3 and 4 seem also questionable.